关于数据同步
同步流程异步化是提升程序响应、服务解耦的一个非常常用的手段。而对于某些业务来说,异步是唯一的选择,比如支付业务。当拿到某个订单的交易结果时,该结果并不代表最终的支付结果,而支付公司会通过回调或者由调用方轮询访问接口获取真实的支付结果。
笔者所涉及的项目中,同样涉及到“交易——对账——数据”这类不能实时获得数据的问题。用户的操作调用合作方的接口产生了交易之后,新的交易数据生成在合作方的数据库里(即使是合作方,也不会实时得到支付结果,最终会与银行打交道)。如何在用户无感知的情况下进行数据的同步,是提高用户体验的一个关键点。在项目研发过程中经历了许多轮的讨论与实践,现在笔者将数据同步功能的发展历程简单介绍一下。
第一个版本
起初的版本,用户访问交易数据,数据流程图如下所示:
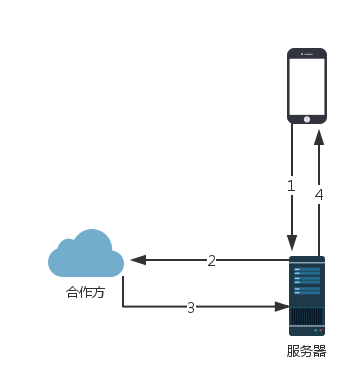
服务器仅作为路由转发客户端的请求给合作方,将合作方返回的数据返回给客户端。这种方案几乎满足不了任何产品需求,唯一的好处是实现简单,上线周期短。
第二个版本
由于清楚了第一个版本的劣势,从这个版本开始,我们需要将数据存入自己的数据库,提供丰富的参数供客户端访问,以实现多样的产品需求,数据流程图如下所示:
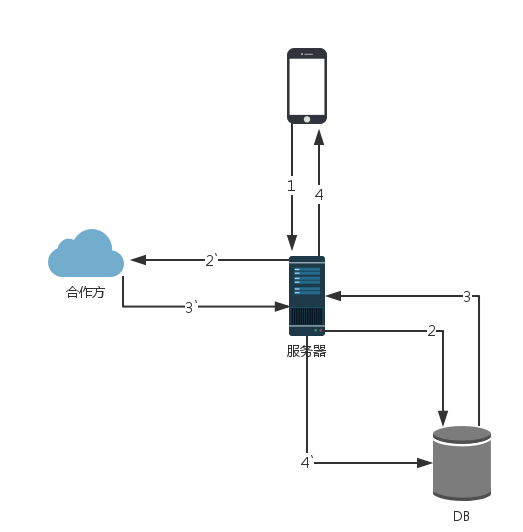
注:本文中的所有图中,数字n与n`是异步关系,无先后顺序。
当客户端请求查询交易数据接口时,服务器先将数据库内的数据返回,然后启动一个异步的同步任务更新数据。
异步更新程序会检测该用户是否在不久之前同步过,如果否则执行同步,是则忽略同步请求,节省服务器资源。
较第一个版本而言,本方案响应更快(除去了第三方接口的访问时间),同时能满足更多样化的需求。然而缺点也是明显的:当用户不使用客户端时,数据依然是旧数据,客服经常会收到用户的投诉电话。
第三个版本
在第二个版本的基础之上,我们引入了更多“触发点”的概念,即用户在操作某些功能的时候,由客户端调用一个接口,通知服务器该去同步用户数据了。
数据流程图与第二个版本的图一致,通过更频繁的同步让数据持续更新。
常用的触发点有:用户打开app(如登录、解锁手势密码)、发生交易(购买、赎回、撤销订单)、查询交易数据(查看资产、交易记录)。
通过上述触发点的触发同步,用户的投诉已经明显减少了,效果良好。但是该版本功能与上版本功能的核心思想一致,唯一不同的是该版本的触发点比上版本的触发点丰富许多,所以依然解决不了用户不使用客户端的情况下数据不会更新的问题。
第四个版本
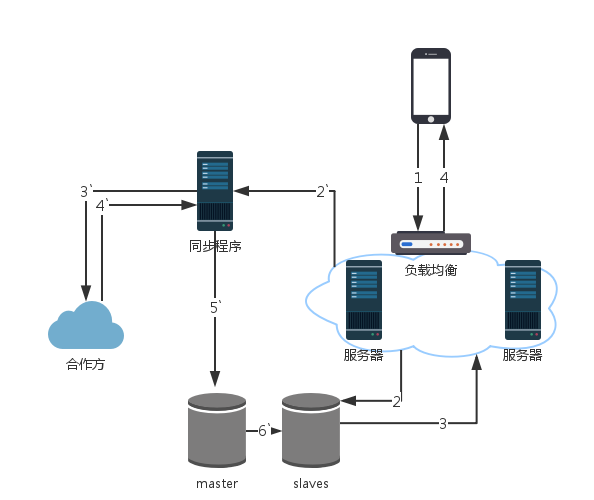
到目前为止,查询服务及后台异步的同步任务处在同一个程序中。接口访问量已经逐渐上来了,所以是时候做点架构上的调整了。
第一步:数据库主从读写分离。
第二步:查询服务增加机器,使用阿里云的负载均衡。
第三步:分离查询服务及同步程序。
所以整个架构就变成了下面的样子:
第五个版本
在上个版本中,触发点建立在用户主动的行为上。在这个版本,我们引入了定时任务。类似余额宝,收益数据每日更新,所以服务器负载最低的凌晨2点-5点,我们的定时任务会把全量交易用户的交易数据更新一遍。数据流程图如下所示:
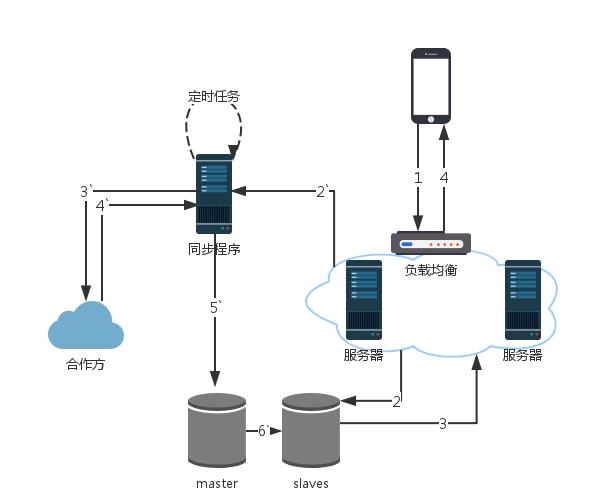
在这个版本,只要合作方可以承受大批量集中式的接口访问,就能很好的解决之前版本的问题,用户在不使用客户端的时候数据依然会自动更新。
第六个版本
第五个版本的全量交易用户数据的同步,造成了服务器资源的浪费,同时合作方也不时向我方抱怨。
由此,我们引入了“交易用户等级”的概念,不同等级的用户会有不同的同步频率,典型的等级有:羊毛客(仅低额交易过一次)、通过活动吸引的用户(有活动才交易,没活动不交易,羊毛客属于最低档次的活动用户)、活跃交易用户(用户每周都会有交易)。
针对活跃交易用户,更新频率至少每天一次。活动用户及羊毛客则根据同步结果动态调整更新频率,如一开始1天一次,当多次同步回来的数据为空时(无持仓),则频率降为2天一次,依次循环,直到同步到了有效数据,更新频率才还原为1天一次。
第六个版本的方案在第五个版本基础上,通过统计交易数据、交易频率,对交易用户打上了不同等级的同步标签,过滤了大部分羊毛客及活动用户,让服务器资源集中为活跃交易用户服务。
第七个版本
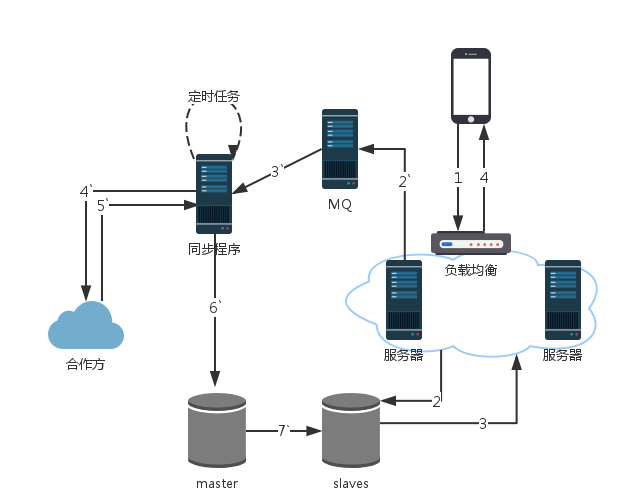
第七个版本为技术驱动的版本。触发式的任务,更应该关注的是一种通知,而非其处理过程,所以作为查询服务,不应该了解同步程序的接口细节。同时,当上游用户请求过多时,会造成同时需要同步的任务过多。因此,将接口调用改成消息队列,主要是为了解耦和流量控制(可根据消费能力投递消息)。
到了这个版本,程序调用关系如下
展望
至此,用户数据同步程序的演变告一段落。笔者相信在不久之后,同步程序就需要多机部署。而引入集群的架构之后,问题会接踵而来。
先来看看数据重复的情况:当某台机器接收到消息执行同步时,另外的机器也收到了消息,这时,为了防止多个程序同时执行同一个用户同步请求造成数据错乱或者重复,需要有所处理。
方案一:可以在数据库建立用户id和流水号的唯一索引,通过数据库保证数据不重复。但是这样做会产生大量的错误和错误日志,性能极其低下,而且单个用户的数据根本就不需要同时同步多次,造成服务器资源浪费。
方案二:通过数据库模拟分布式锁,如memcache的cas,mysql的乐观锁等。当且仅当线程成功更新标识字段时,表明该线程已经获得了锁,可以执行同步逻辑,否则抛弃掉本次同步请求。
方案三:采用zookeeper、chubby等解决分布式一致性的框架,实现自己的分布式锁服务。
除了数据重复之外,还要诸如高可用、负载均衡等问题需要解决。