前言
缓存在计算机的世界中是一个非常宽泛的概念,因为处处是缓存的身影。操作系统可能缓存DNS的解析结果,浏览器可能缓存页面静态元素,用户访问的资源可能缓存在CDN中, CPU可能会缓存操作数所属的内存块,数据库的查询结果也可能是缓存好的。总之不管是在系统架构中的哪一层级,都有缓存的实现。所以,抛开具体应用谈缓存是没有意义的,那样过于空泛,但可以肯定的是,所有的缓存都是利用了数据的冗余提高性能,空间换时间,计算机的世界充斥着trade off。
本博文基于项目中的实际应用整理而来,仅讨论在DB和业务代码之间的缓存服务,主要分析笔者经历的项目中,根据不同的业务,采用了哪些更新策略(注,不讨论缓存的替换策略,如LRU等)。
缓存更新策略
缓存更新策略,主要包含以下几种:Cache Aside、Read/Write Through、Write Behind、Refresh Ahead。
1.Cache Aside
业务系统中最常用的策略就属Cache Aside了。逻辑非常简单:
- 读操作如命中缓存,则返回缓存内容。否则查询数据库,将查询结果存入缓存,再返回查询结果。
- 写操作先将数据库更新,待更新成功后,再清除缓存。
在写操作中,如果先清除缓存,再更新数据库,缓存中出现脏数据的概率会大很多。因为读操作通常比写操作多的多,并且写操作会因为数据库锁(表锁还是行锁,视表的存储引擎和索引使用情况而定)和索引更新操作而比读操作慢的多,以至于在写操作清除缓存之后更新数据之前,很可能已经被另一个读操作将脏数据更新到了缓存中。
在笔者的项目中,Cache Aside由spring-context提供给的Cacheable和CacheEvict注解实现。
//需要缓存时,用Cacheable
@Cacheable(value = "index")
//删除缓存时,用CacheEvict
@CacheEvict(value = "item", key = "'item_' + #id")可以从注解的注释中看到其执行的逻辑属于Cache Aside策略:
Cacheable: If no value is found in the cache for the computed key, the method is executed and the returned instance is used as the cache value.
CacheEvict: Whether the eviction should occur after the method is successfully invoked (default) or before. The latter causes the eviction to occur irrespective of the method outcome (whether it threw an exception or not) while the former does not.
使用注解的方式,代码会简单许多,但同样会引入其他问题,如调试、缓存问题跟踪、缓存过期时间等。spring-context提供了一套接口,以及少量的默认实现, 比如org.springframework.cache.support.AbstractCacheManager,内部维护了一个ConcurrentMap私有变量,实现的是JVM内存缓存。如果需要使用其他缓存中间件,如redis, 则许引入其他依赖包(spring-data-redis)或者自行实现。
关于使用Cacheable的过期时间问题,建议模仿SPEL实现一个简易的固定格式的配置规则,比如@Cacheable(value = “index_{expire:50}”)。 通常有一点源码阅读经验的工程师,对现有框架做细微扩展,不是一件难事。
除了上述问题之外,使用框架处理缓存,当命中缓存时,可能不会再执行目标方法,导致目标方法内的日志缺失,对跟踪问题会造成一定的影响。
抛开具体的实现方式,采用Cache Aside策略的业务代码需要关注多个数据源,每个业务模块都需要维护多个数据源的配置,对业务规模庞大的系统而言,是一笔不小的成本。
2.Read Through
与Cache Aside稍有不同,业务层可以把对数据源的维护委托给独立的存储代理服务。 当业务层访问某个需要缓存的key时,如果没有命中缓存,代理服务则会访问数据库,将结果存入缓存,再返回结果。
对于业务层来说,不需要关心数据是存于内存还是数据库,也不用关心数据在存储系统内的格式,只需要约定的结构体序列化和反序列化即可。 将权责细分之后,业务层的执行流程更加清晰,也不会影响到业务层的日志记录。
3.Write Through
与Read Through类似,业务无需关注存储逻辑,存储代理服务将全权负责数据的写入工作。当某个写操作命中缓存时,需要先更新缓存,再更新数据库。如果没有命中缓存,则直接更新数据库。
Read Through/Write Through的大致流程图如下图所示:
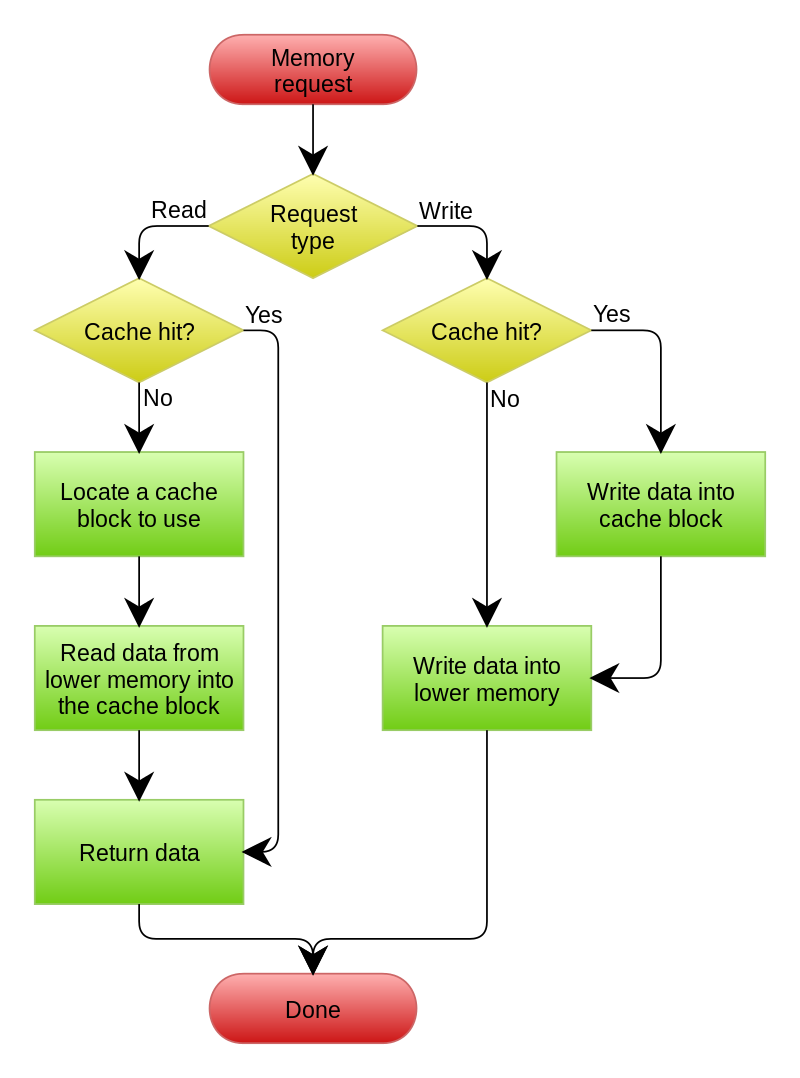
Read/Write Through相较于Cache Aside策略,并无性能上的提升,区别在于Read/Write Through策略的服务更专注,更偏向微服务的架构,当然调用链层级也更深,对服务治理有更高的要求。
4.Write Behind
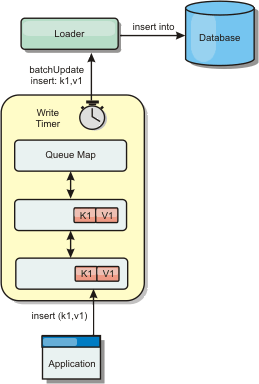
Write Behind策略在更新数据的时候,只更新缓存,更新成功之后立即返回,由存储代理服务自动持久化。由于业务不需要等待持久化的结果,所以Write Behind相比Write Through会有更大的吞吐量。 Write Behind策略的应用非常广泛,如内存与硬盘文件之间的Page Cache、内存缓存服务的持久化策略、异步输出日志等。Write Behind增加了数据落地的延时,换取更高的吞吐量,同时,对相同数据的多次更新,可以合并为一个实际更新,对数据库也起到了保护的作用。
在笔者的项目中,将服务请求错误率等统计数据存于redis内,由另外的定时器每隔一定时间更新至数据库中。 由于在数据更新和落地之间存在时间差,可能会存在数据最终无法落地的情况。需要评估使用此策略的业务是否对数据的准确性非常敏感,因为服务运行情况统计的信息不需要很准确,所以采用Write Behind策略是很好的选择。
Write Behind策略的流程如下图所示:
5.Refresh Ahead
Refresh Ahead策略要求存储代理服务可以在请求到来之前对数据预先缓存。 在服务启动时,可以先按照配置预热,在服务运行过程中,对热点数据动态学习(和JIT判断热点代码类似),以决定当数据过期之前是否自动重新加载数据。 此策略较上述策略的区别在于主动预测,而非被动请求。
在实践中,可以自己编写定时器扫描热点数据的缓存TTL,也可以采用类似redis的Redis Keyspace Notifications服务, 以决定数据是否需要重新加载。
Refresh Ahead策略可以预先缓存好数据,提供更低的服务延时,广泛用于各种配置服务:当服务启动时预热数据。然而,如果不能准确预测数据的使用情况, 极端情况下,缓存中存满了非热点数据,这时不但需要频繁的缓存置换,还需要不断请求数据库,会对系统整体造成更大的负面影响。
总结
目前通用的缓存更新策略,并不是什么新的设计,正如左耳朵耗子所说,其最初源自于最古老的系统原理。在实际的项目中,我们只需要遵循工程上的最佳实践即可,不需要重复造轮子。
参考文献
[1] 陈皓.缓存更新的套路[EB/OL].https://coolshell.cn/articles/17416.html,2019-06-28.
[2] Read-Through, Write-Through, Write-Behind, and Refresh-Ahead Caching[EB/OL].https://docs.oracle.com/cd/E15357_01/coh.360/e15723/cache_rtwtwbra.htm#COHDG5177,2019-06-30.